Project 2: Riddles in the Dark
Difficulty Level: ★★★☆☆
Due date: April 16 23:59
Updates and Revisions
- [April 15 20:40] Added clarification for negative offsets.
- [April 13 00:23] Added Gradescope submission instructions.
- [April 11 16:35] Added clarification for GitHub clone link.
- [April 10 15:31] Added clarification for negative offset results in the decryption process.
Table of contents
- Learning Goals
- Getting Help
- Introduction
- Before We Begin…
- The Encryption Process
- The Decryption Process
- Getting Started
- Compiling
- The Reference Program
- The Starter Code
- Testing and Debugging Your Code
- Submission Guide
Learning Goals
In this assignment, we will–
- practice using loops and conditionals,
- learn the basics of strings in C,
- run programs from the command line,
- test our own code for correctness, and of course,
- practice using the terminal and vim some more.
Getting Help
You are always welcome to come to either instructor or TA office hours. Both of which are listed on the course website. In office hours, however, conceptual questions will be prioritized.
If any part of this writeup is ambiguous or confusing, please ask us to clarify on Edstem!
If you need help while working on this PA, make sure to attend tutor hours. Tutor hours policy can be found in the syllabus.
You can also post questions on Edstem.
Introduction
For your first proper C programming assignment, you will be implementing a simple text cipher to encrypt and decrypt secret messages so that Mark Zuckerberg can’t read the messages between you and your friends.
So, what is a cipher?
Example Cipher: The Caesar Cipher
Text scrambling is a very basic way to encrypt messages. You may have heard of the Caesar Cipher, which works by shifting the alphabet by a certain offset.
Suppose we have a simple Caesar cipher with an offset of 3, then every letter in the encrypted text would in fact represent the letter that was originally 3 positions down the alphabet. For example, when you see the letter ‘A’ in the encrypted text, it actually represents ‘D’.
Here’s a more concrete example of a caesar ciphre in action (offset=3).
Alphabet: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Encrypted: X Y Z A B C D E F G H I J K L M N O P Q R S T U V W
---
Plaintext: THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
Ciphertext: QEB NRFZH YOLTK CLU GRJMP LSBO QEB IXWV ALD
Your Task: The Affine Cipher
Don’t be scared off by the name. (It’s pronounced /əˈfaɪn/ by the way.) This is still a relatively simple cipher following roughly the same principles as the Caesar cipher shown above. Here’s how it works:
First, instead of a simple offset, there are now two integer keys for the cipher: key1 and key2. Both of these should be relatively small non-negative integers.
You can read more about the Affine cipher on Wikipedia, but–
Before We Begin…
Read the whole thing!
The Importance of Reading
One of the best ways to suffer in CSE 29 programming assignments is not paying enough attention to the assignment specifications. Yes, these documents can be very long, but they are long because they contain a lot of useful information that you will need to successfully complete the tasks.
Reading is one of the most important skills to have as a software engineer. Not only should you become comfortable with reading long specifications, you also need to be able to read and understand documentations, which you will have plenty of opportunity to practice throughout this quarter.
Do not shy away from reading! Read this whole document thoroughly!
Incremental Development and Testing
Another good way to suffer in CSE 29 is to not follow the principles of incremental development and testing.
A very critical skill we hope you will obtain after CSE 29 is that of problem decomposition: how to break down a complicated problem into smaller parts? In some ways, we help you with that in CSE 29 by providing you with structured skeleton code for each assignment, so that you can see what the smaller tasks are for each PA. But with that, you still need to take an incremental approach to programming.
Put simply, don’t write too much code at once without testing. If you have written a few lines of code, think about how you can test it to make sure everything is working as intended before moving on to the next part.
If you don’t, bugs will inevitably pile up and bury you underneath.
You should never find yourself compiling and running your code for the first time only after thinking you have finished coding the entire assignment.
I speak from experience.
Follow our advice!
Please?
Did you skip this section? If so, scroll back up and read it! Pretty please.
The Encryption Process
Before we talk about the encryption algorithm, note that each letter can be represented by a number. In lecture, you should have learned about the ASCII encoding, in which each character corresponds to a integer value. For instance, the lower case 'a' is encoded as 97, 'b' as 98, 'z' as 122, etc.
With that in mind, our encryption program–
- Converts all upper case letters to lower case first,
- Only encrypts english alphabet letters, and
- Computes using the offset of letters, rather than the ASCII values directly.
Calculating The Offset
For every letter, we need to compute its offset in the english alphabet, namely, how far away it is from the letter 'a'.
This is actually quite easy to do in C. You can simply do
// example: calculating the offset of the letter 'x'
char c = 'x';
int off = c - 'a';
The Algorithm
The encryption algorithm is simply taking the offset of each letter and doing some math involving the two keys to get a new offset, which will correspond to the encrypted letter. Let’s break down this process:
Let’s use the variable c to represent the letter we are trying to encrypt. Here are the steps:
- calculate the offset of
cin the alphabet - multiply the offset by
key1, - add
key2to the result from the previous step, - take the modulus of the sum from the previous step divided by 26 to get an offset,
- use this new offset to get the ASCII value of the encrypted letter.
Or, if you prefer a more mathematical representation:
\[encrypt(c) = `a’ + ((key_1 \times offset(c) + key_2) \mod 26)\]Example
Say we have key1 = 3 and key2 = 6. To encrypt the letter 'c', which has an ASCII value of 99, we do the following:
This gives us the letter 'm' as the encrypted letter.
The Decryption Process
In some ciphers, the decryption algorithm is simply the reverse of the encryption algorithm. However, the Affine cipher does not have this symmetry.
To decrypt a letter c using two keys key1 and key2, here are the steps:
- calculate the offset of
cin the alphabet, - subtract
key2from this offset, - multiply the previous result with the modular multiplicative inverse of
key1, - take the modulus of the result from the previous step divided by 26 to get the new (decrypted) offset,
- use the new offset to get the ASCII value of the decrypted letter.
Again, as a math formula, this looks like:
\[new\_offset = key_1^{-1}(offset(c) - key_2) \mod26\] \[decrypt(c) = `a’ + new\_offset\]where \(key_1^{-1}\) represents the modular multiplicative inverse of key1.
It is possible that the new (decrypted) offset \((key_1^{-1}(offset(c) - key-2) \mod 26)\) obtained from step 4 is negative, in which case, you should increment the offset by 26 (the vocabulary size) to make sure the offset still fall within the range of the alphabet (0-25).
The Modular Multiplicative… What?
Yes, I see you might be (quite understandably) confused. Don’t worry. You do not need to implement this part.
But there is something you should know: For our case, a modular multiplicative inverse only exists if key1 and 26 (the size of the alphabet) are coprime. This means that we are limited in our choice of key1.
“What the —?”
At this point, you might be realizing that this is, in fact, a really weak cipher.
In the starter code, you will be given a function that computes the modular multiplicative inverse.
Getting Started
Now that we have a decent understanding of how the Affine cipher works, it’s time to implement our own.
Starting this week, all our programming assignments will be hosted on GitHub classroom. Use the following link to accept the GitHub Classroom assignment:
Click here to accept this GitHub Classroom assignment. (Right click to open in new tab.)
Once the assignment is accepted, you will see a repository generated for you with the starter code for this PA.
You should now clone this repository into your ieng6 workspace. Remember the cse29/ directory you created on ieng6? It would be a good idea to clone it there. If you do not remember how to clone a repository, check out Lab 2 again.
You should have set up ssh authentication for your GitHub account during lab. To clone using ssh authentication, click the green “Code” button and select the “SSH” tab. Use the URL there to clone the repo.
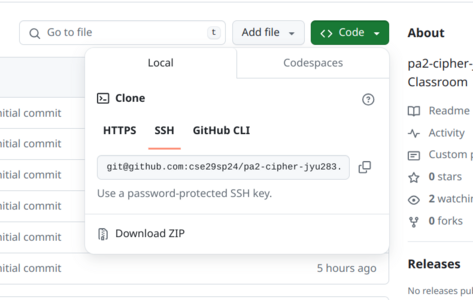
Once you have cloned the repository, you can cd into it, where you will find the following files:
cipher.c: The starter code,ref-cipher: A reference program,plain.txt: A file containing some example plain text,encrypted.txt: A file containing the encrypted version ofplain.txt,README.md: A basic README file for this project.
Compiling
To compile your program, use the following command:
$ gcc -o cipher -Wall -std=gnu99 cipher.c
As a quick reminder for what the command does:
- the
-o cipherpart specifies the name of the executable should becipher. - The
-Wall(warn-all) option turns on all warning messages. - The
-std=gnu99part is new. This specifies the C standard we wish to use. (A standard as old as Jerry!) - The
cipher.cpart specifies the source file from which to compile our program.
The Reference Program
In your repository, you will find an executable program named ref-cipher. This is compiled from our solution code. Whenever you are unsure about some implementation details (e.g., handling certain corner cases), you can check the behavior of this program.
This reference program is only compiled for the ieng6 server. You maybe able to get it to run on your own device, but you should be doing the assignment on the ieng6 server.
You can start by playing around with the reference program. If you simply run the program like ./ref-cipher, you will see the following message:
$ ./ref-cipher
Usage: cipher [-e|-d] key1 key2
This is telling you how the program should be run. Recall that the cipher can either encrypt or decrypt a message. The -e or -d flag tells the program which mode it should operate in. key1 and key2 specify the two keys required for the cipher algorithm.
For instance, if we wish to encrypt messages using the keys 3 and 7, we can run the reference program like so:
$ ./ref-cipher -e 3 7
If you type this in and hit <Enter>, you will see that nothing happens. But don’t worry, the program is simply expecting your input. So you can type in your message, and press <Enter> again. Now the program will encrypt the message, and again wait for your input.
You can keep entering messages to encrypt/decrypt. The program runs on a loop to continually accept and process your input. (Just like the shell!) If you wish to end the program, you can either press <Ctrl-C> to kill it, or <Ctrl-D> to exit more gracefully.
More specifically, <Ctrl-C> sends a signal called an interrupt signal (SIGINT) to forcefully terminate the program. Whereas <Ctrl-D> sends an End-of-File (EOF) signal, which more gracefully tells our program that there are no more input to process.
Example Input/Output
Here are some examples of running the reference program:
Encryption: Running the program in encrypt mode with keys 3 and 6, we type in three messages for the program to encrypt:
- Not all those who wander are lost.
- My precious!
- Go where you must go, and hope!
Here’s what it looks like from the terminal–
$ ./ref-cipher -e 3 6
Not all those who wander are lost.
twl gnn lbwis ubw ugtpsf gfs nwil.
My precious!
qa zfsmewoi!
Go where you must go, and hope!
yw ubsfs awo qoil yw, gtp bwzs!
(Notice all input letters are converted to lower case after encryption.)
Decryption: Running the program in decrypt mode with the same keys (3 and 6) allows us to decrypt the secret messages we obtained earlier:
$ ./ref-cipher -d 3 6
twl gnn lbwis ubw ugtpsf gfs nwil.
not all those who wander are lost.
qa zfsmewoi!
my precious!
yw ubsfs awo qoil yw, gtp bwzs!
go where you must go, and hope!
Invalid key1: Running the program with an invalid key1 value: (Recall that key1 must be coprime with 26 for the cipher to be reversible.)
$ ./ref-cipher -d 2 18
Error: invalid key1 value.
The Starter Code
The starter code (cipher.c) can be quite intimidating at first glance, so let’s try to break it down.
The main() function
All C programs start at the main() function, so we will do the same:
The main() function is similar to what you are no doubt familiar with in Java. The existing starter code in the main() function is there to handle command line arguments.
Remember command line arguments? That’s what the -e key1 key2 part is in the command to run the cipher program. You will learn how to do this yourself in the upcoming weeks. For now, let us take care of it for you. If you are interested, you can read more about using getopt() in C.
Overall, the main() function should do the following:
- Process command line arguments,
- Check key1 is valid, and
- Run a loop to process and encrypt/decrypt input.
Step 1 is already done for you.
There are many variables declared at the start of the main() function. You should pay attention to the following:
char buf[MAX_INPUT_SIZE]: the character array to hold the input message,int key1, key2: the two integer keys,int mode: the program mode (decrypt/encrypt).
Configuring the mode
What you need to understand about this part of the starter code is that the int mode variable keeps track of if the program is running in encrypt or decrypt mode. We have created two macros (think of these as constants) named ENCRYPT_MODE and DECRYPT_MODE to make things more readable. ENCRYPT_MODE has a value of 0 and DECRYPT_MODE has a value of 1.
In the while loop containing the getopt() function call, you will see our code for setting the mode variable.
Setting the keys
Again, this is handled by our starter code using the strtol() function. You do not need to understand this function yet.
Task 1: Checking for valid key1
Here, you will find your first /* TODO */ comment.
Recall that a valid key1 should be coprime with 26. We have written a function to check this for you:
int valid_key1(int key1);
This function returns 1 if key1 is valid, 0 if not. You should write an if condition with that function to check if the key1 obtained from the command line arguments is valid. If it is not valid, you should print an error message to standard error (stderr), and exit the program with an error code.
The standard error is an output stream where error message are commonly written to. To be more precise, it is a file descriptor, but we won’t get to that anytime soon in this class. When you use printf, you are writing to a stream called standard output.
To print a message to stderr, we need to use the fprintf function. The following (incomplete) code snippet is what you need to handle an invalid key as described above.
if (...) {
fprintf(stderr, "Error: invalid key1 value.\n");
return EXIT_FAILURE;
}
You need to figure out what goes inside the if condition.
Task 2: Encrypt/Decrypt
Continuing down the main() function starter code, you will find a while loop that calls the fgets() function. This is where we handle user input from the terminal.
Again, you will get to work with the fgets() function later in this quarter to handle user input yourself. For now, just know what it is doing. Don’t worry too much about how.
Inside the body of this while loop, you will find a bit of code that
- Computes the length of the input, and
- Trims the newline character (
\n) at the end of the input.
When you hit <Enter> in the terminal, what you are really doing is typing a newline character (\n). That’s why it’s included in the input buffer. The starter code gets rid of it.
Now, your task is to process the input string stored in buf.
To do this, we basically need to process one character at a time. So, create a for loop that iterates over each character in the buf character array. The length of the array has already been computed for you and is stored in the len variable.
For each character in buf, you should do the following:
- Convert it to lower case. You can use the
tolower()function here. Don’t know how? Google it! - If in encrypt mode, call the
affine_encryptfunction to get the encrypted character. If in decrypt mode, call theaffine_decryptfunction to get the decrypted character.
Note that all conversions/encryptions/decryptions happen in-place, which means modifying the character element in buf directly!
Now, let’s look at the affine_encrypt and affine_decrypt functions.
Task 3: The affine_encrypt function
This function takes three arguments:
char c: the character to encrypt,int key1: the first integer key,int key2: the second integer key.
The return value of this function is the encrypted character.
The encryption algorithm is as described earlier. Your task is to implement it in C.
Note that the encryption algorithm is only applied to lower case characters. If the character c is not a lower case letter, no encryption needs to be performed, and you can just return the character as-is.
To check that a character is a lower case letter, you may use the islower() function.
Task 4: The affine_decrypt function
The arguments and return value are the same as the affine_encrypt function.
The decryption algorithm is the same as described earlier. The important thing to note here is that we have provided you with a function to compute the modular multiplicative inverse:
int mmi(int key1);
You can find this function earlier in the file. You do not need to understand its implementation. Just call it with key1, and you should get the inverse value to use in the algorithm.
And, just like the affine_encrypt function, if a character is not a lower case letter, you can skip the decryption and return it as-is.
Task 5: Printing the encrypted/decrypted string
After a message is encrypted/decrypted, you should print it to the terminal.
Testing and Debugging Your Code
Now, we come to the most important part. How to test your code?
To test your code, you need to be able to run it. So the first step is compiling and sorting out any compiler errors you may run into.
Taking care of compiler errors:
- Sometimes, the compiler is nice enough to tell you how to fix the code.
- If not, google it.
- If google doesn’t help. Ask us for help!
Once your code is compiled into the executable cipher, you can run it just like you would run the ref-cipher program.
Ideally, the first thing you finished implementing should be checking for invalid key1 values.
Here are the only valid key1 values that are coprime with 26: 1, 3, 5, 7, 9, 11, 15, 17, 19, 21, 23, 25. Any number not in this list would be invalid for key1. (key2 can have whatever non-negative integer value).
If that’s working, you can move on to testing your actual encrypt/decrypt features.
Testing Incrementally
You don’t have to finish the entire affine_encrypt function before testing your code. That would be a terrible idea especially for beginner programmers.
Here are some incremental checkpoints you can test for:
- When you write a for loop to iterate over all the characters in the
bufcharacter array, are you actually looping over all the characters? Try printing them out to check! - Are you able to convert upper case letters to lower case successfully?
- Are you calling
affine_encryptandaffine_decryptfunctions correctly? You can check this by placing a print statement in these functions. But make sure to remove any testing print statements before submitting.
These are some good examples to get you started. You should try to think of similar checkpoints when you are implementing the actual encrypt/decrypt functions.
Testing Using Input/Output Redirection
In the first programming assignment, you saw that the output of a program could be redirected to a file:
$ objdump -d hello > executable.dmp
Similarly, we can also redirect input from a file (instead of from the keyboard).
We have provided two files called plain.txt and encrypted.txt in the starter repository. You can actually use these files as input to your cipher program (or the reference program).
Let’s run the cipher to encrypt text with the keys 3 and 6. Except instead of typing in the message from the keyboard, we will direct the contents of the file plain.txt as the input of the cipher program:
$ ./ref-cipher -e 3 6 < plain.txt
lbfss fetyi vwf lbs snrst-ketyi otpsf lbs ika,
isrst vwf lbs pugfv-nwfpi et lbsef bgnni wv ilwts,
tets vwf qwflgn qst pwwqsp lw pes,
wts vwf lbs pgfk nwfp wt bei pgfk lbfwts
et lbs ngtp wv qwfpwf ubsfs lbs ibgpwui nes.
wts fety lw fons lbsq gnn, wts fety lw vetp lbsq,
wts fety lw jfety lbsq gnn, gtp et lbs pgfktsii jetp lbsq
et lbs ngtp wv qwfpwf ubsfs lbs ibgpwui nes.
As you can see, the cipher program processed all the lines in plain.txt (which are not shown in the terminal), and printed the encrypted messages.
Similarly, the encrypted.txt file contains lines of encrypted text, which you can feed into the cipher program in decrypt mode to reveal the original messages. The keys are 3 and 7 for decryption.
You are also encouraged to create your own test files.
Committing Using Git
As we have explained in discussion and in lab, git is a great way to do version control. And it goes naturally with incremental development.
Every time you finish a small functionality, you should commit your code.
To commit your code, you need to be in your code repository directory, and run the following command:
$ git commit -am 'commit message here.'
The -am flag is a combination of -a (add all files) and -m (commit message).
For the commit message, you should write something that is at least minimally meaningful. Here are some decent examples:
- Implemented key1 validation and error message.
- Fixed minor bug with key1 validation.
- Implemented loop to covert all input to lower case letters.
- Implemented basic version of encrypt.
Here are some not so great examples:
- .
- asdfasd
- why won’t you work
- aaaarrrgggghhh
- stupid bug
- ******* ****
- wrote some ****
All of these are commit messages that I have written throughout my short career, but you should aim to write yours more like the first list. At least when you are in a decent mood.
Pushing to GitHub
Every once in a while, maybe even after each commit, it would be a good idea to push your progress to GitHub in case the CSE building burns down and the ieng6 servers are destroyed.
To do that, navigate to your code repository directory, and run
$ git push
Simple as that.
Submission Guide
Submitting from GitHub
Unlike the first assignment, you no longer need to download anything from ieng6. (scp usually causes a lot of frustration throughout the quarter.) Instead, you can submit the assignment directly from your GitHub repository.
To do that, you first need to make sure that the most up-to-date version of your code has been pushed to GitHub. If you want to double check, go to the GitHub web page and find your repository to make sure the code changes you made on ieng6 are actually all there.
Having done that, go to Gradescope and find the submission page for this PA. When you submit the assignment, you will see the option to submit from a specific GitHub repository. You will need to link your GitHub account first, after which you should be able to find your pa2 repository. Select it, and choose the main branch.
We have not discussed branching in git yet, so unless you know what you are doing, you should only see main for branch options.
Gradescope Autograder
You score will always be 0 before the deadline! Please see the results for specifc test cases to understand how your code performed.
After you submit your PA on gradescope, you’ll notice there are a set of public test cases and a (significantly larger) set of hidden test cases. As the names would imply, you will only have access to the public test cases, though you will be graded on the result of ALL the test cases.
The reason we hide these test cases is not to cause you suffering, but rather to improve your debugging skills by asking you to think critically about possible inputs and expected behaviors.
Generally, one good way to come up with edge cases is to review the requirements for your code. In this case, this would be your PA write-up. For example, you’ll see that Task 2 requires you to convert each uppercase letter to lowercase. If you haven’t started testing, testing if your code works with both upper and lowercase letters is a good start. What other requirements can you find in the write-up? How can you test your program to make sure your program follows these requirements? Are there any possible edge cases you can think of that the write-up didn’t mention? Remember that you have access to a reference solution (something that won’t always be there!), which you can use for this PA to see what the test cases you come up with should return.