Project 4: Webster Dictionary Defines PA 4 As Reasonably Difficult
Reading time: 10 minutes
Difficulty Level: ★★★★☆
Due date: May 09 23:59*
Because of the upcoming midterm, you have an additional week to complete this PA. However, doing this PA will give you a much better understanding of concepts that will be heavily featured on the midterm. So do not wait until after the exam to start!
Updates and Revisions
- [May 6 17:11] Extended deadline due to campus disruptions.
- [May 4 15:01] Added Gradescope submission instructions.
- [May 1 15:23] Added section on
string.hlibrary functions. - [May 1 12:18] Added Mid-Quarter Survey section.
- [April 30 18:09] Added section on testing and valgrind.
- [April 25 14:13] Updated GitHub Classroom link.
- [April 25 10:21] Updated GitHub Classroom link.
Table of contents
Mid-Quarter Survey (3%)
This survey is worth 3% of your PA 4 grade. Please complete it as soon as possible.
Complete the mid-quarter survey here.
Learning Goals
In this assignment, we will
- practice dynamic memory allocation,
- use pointers with structs,
- debugging pointer code using gdb,
- finding memory errors using valgrind,
- implement a linked list,
- learn how to use a code formatter, and of course,
- practice using the terminal and vim some more.
At this point in the quarter, you should really know how to use gdb. Hopefully through lab and previous PAs you have gained a decent amount of experience with it.
You need to write a lot of code for this PA, and it is inevitable that you will run into a decent amount of bugs (and that’s perfectly fine). But not knowing how to use gdb well will make this PA 5 times harder than it needs to be!
Introduction
Our objective this week is to create an interactive dictionary in the command line. You do not have to implement the interactive part, as we have included in the starter code a fully-featured interactive shell. What you do have to implement is the underlying database containing a list of words loaded from a formatted dictionary file.
Linked Lists
Linked lists are one of the most fundamental data structures in computer science. Unlike an array, where the elements are stored continuously in memory, elements in a linked list can be anywhere, and the ordering is maintained by a pointer in each element that points to the next element (hence the name linked list).
Here’s an illustration of what a linked list looks like:
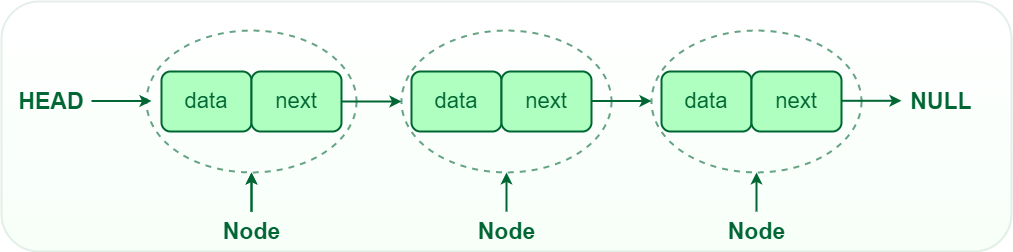
(Source: GeeksforGeeks: Understanding the basics of Linked List)
In this programming assignment, you will be creating a linked list interface.
Getting Started
The starter code for this assignment is hosted on GitHub Classroom. Use the following link to accept the GitHub Classroom assignment:
Click here to accept this GitHub Classroom assignment. (Right click to open in new tab.)
Just like last time, clone the repository to your ieng6 server. (Do NOT clone the repo to your local machine.)
The Code Base
Just like in PA 3, the code base for our new assignment consists of multiple C files. The dictionary.h header file is our “interface” file, to use a more familiar Java analogy. The header file defines critical data types for our program and outlines the function interfaces that you need to implement.
dictionary.c is where you will write your implementation for the functions declared in the header file. It is also the only file that you should be editing for this PA. The functions implemented here are then used by the driver in sh.c to create the interactive command-line dictionary program.
If one C file wants to use a function written in another C file, the function must be declared in a header file, which should then be included (#include) in both C files, acting as a bridge connecting the two at compile time. We never include .c files directly!
Once again, we have provided you with an executable program compiled from our reference implementation: ref-webster. Your program should match the behavior of this reference implementation in every way.
To begin, read through the dictionary.h header file. We will go through the contents of this header file below.
Data Type: struct dictionary
struct dictionary, as the name suggests, defines a dictionary. A struct dictionary instance contains two fields: size keeps track of the total number of words, and list points to the head of a linked list of all the words in the dictionary.
Data Type: struct dict_entry
struct dict_entry defines an entry in the dictionary. Each entry also constitutes one node in the aforementioned linked list in struct dictionary. Notice that there are two strings in this struct:
wordis a string that holds the word itself; it is a character array built into the struct itself,definitionis a pointer to a string containing the definition ofword.
This means when we create a new dictionary entry, we can directly copy the word into the struct, but we need to separately allocate a string buffer dynamically to hold the definition. It is also important, consequently, to free that dynamically allocated definition string when we free the dictionary entry itself.
The Dictionary Interafce
You only need to implement one thing for this assignment: the entire linked list interface for the dictionary as described in dictionary.h:
struct dict_entry *new_entry(const char *word, const char *definition);void free_entry(struct dict_entry *entry);void dict_insert_sorted(struct dictionary *dict, struct dict_entry *entry);void dict_remove_word(struct dictionary *dict, const char *word);void print_word(struct dict_entry *entry);void print_dictionary(struct dictionary *dict);void print_word_list(struct dictionary *dict);struct dict_entry *dict_lookup(struct dictionary *dict, const char *word);struct dictionary *load_dictionary(const char *filename);void free_dictionary(struct dictionary *dict);
You can find the specifications for all these functions as comments in the dictionary.h header file. You should implement all these functions in dictionary.c.
The Interactive Shell
The main function for our dictionary program is written in sh.c. You do not need to modify this file, but we will introduce what it does.
sh.c implements the interactive shell with which we interact with the underyling linked list data structure. THe list of commands are recorded in the print_help() function in sh.c, which can be invoked by typing in the help command, or simply h:
Available shell commands:
(q)uit Quit the dictionary.
(h)elp Show this command guide.
(l)oad Initialize an empty dictionary.
(l)oad [file] Load a formatted dictionary file.
(s)how Show all words in the dictionary.
(s)how [word] Show the definition of a word.
showall Show all words and their definitions.
(i)nsert word def Insert a new word definition into dictionary.
Assume there will be no duplicate entries.
(r)emove word Remove a word from the dictionary.
size Show the size of the dictionary.
When we first compile and run the webster executable, we are greeted with the title and a brief guide to all the built-in commands (reproduced above). At the prompt (webster) , we can enter one of the commands above to work with the dictionary.
Letters enclosed in parentheses are shorthands for their respective commands. E.g., instead of typing the whole word load, you can just type l. This is very similar to how we interact with gdb.
The load command
To begin, we need to load a dictionary file. You can use the load command like so:
(webster) l dict/short
Dictionary loaded with 5 word(s).
Alternatively, you can execute load without a dictionary file as argument, which will initialize an empty dictionary:
(webster) l
Dictionary loaded with 0 word(s).
Under the hood, the load command calls the load_dictionary function. If another dictionary has already been loaded, it would first call free_dictionary on that dictionary and then load in the new one.
The struct dictionary returned from the load_dictionary function is stored in a global variable in sh.c, so there can only be one loaded at the same time.
This command will not work right away, as it depends on the new_entry() and dict_insert_sorted() function, both of which you must implement yourself.
Incremental development is more vital than ever for this programming assignment. You should really think about how you can apply the principles here. You do not want to wait till you have finished both functions before testing it! We have already talked about a wide range of strategies to inspect and validate your code. Try to apply those skills now.
We have provided in the dict/ directory three dictionary files for you to test with. You can begin with dict/short for initial development, as its smaller size makes it more manageable and easier to debug with.
The size command
The size command directoy accesses the size field in struct dictionary. So make sure when you insert/remove words from your dictionary, you are also incrementing and decrementing this size field appropriately.
(webster) l dict/gre
Dictionary loaded with 642 word(s).
(webster) size
642
The show command
The show command can also be executed without arguments.
When executed by itself, it calls the print_word_list() function to print out all the words currently loaded in the dictionary.
(webster) s
fun
gone
heard
protect
these
When called with a word as argument, it calls the dict_lookup() function to look up the definition of the given word. The lookup is case-sensitive.
(webster) s protect
protect
To cover or shield from danger or injury; to defend; to guard; to preserve in safety; as, a father protects his children. The gods of Greece protect you! Shak. Syn. -- To guard; shield; preserve. See Defend.
(webster) s those
Cannot find "those" in dictionary.
The showall command
The showall command calls the print_dictionary() command under the hood, which prints out all the words along with their definitions in the dictionary.
The insert command
The insert command must be called with a word and its definition as arguments. The first word after the command is the word to be added, and everything that comes after is treated as the definition:
(webster) l
Dictionary loaded with 0 word(s).
(webster) i protect To cover or shield from danger or injury.
(webster) s
protect
(webster) s protect
protect
To cover or shield from danger or injury.
The shell program we provided will parse the input for you, and call new_entry() and then dict_insert_sorted() to add the word to the dictionary.
For the implementation of dict_insert_sorted(), you may assume that there will not be duplicate words. All words will also be lower-case only.
The remove command
The remove command must be called with a word. It calls the dict_remove_word() function to try to remove the given word from the dictionary linked list. If the word does not exist in the dictionary, then nothing happens.
(webster) l dict/short
Dictionary loaded with 5 word(s).
(webster) s
fun
gone
heard
protect
these
(webster) r gone
(webster) s
fun
heard
protect
these
(webster) s gone
Cannot find "gone" in dictionary.
(webster) r nonexistent
(webster) s
fun
heard
protect
these
Using string.h Library Functions
To implement this assignment, you will find some functions in the string.h library particularly helpful. Specifically, we would like you to pay attention to strlen() and strncpy().
(The descriptions are taken directly from the Linux manual pages. To access these documentation pages yourself, type in the terminal man strlen and man strcpy. You can do this with other function as well, such as man fopen.)
First, we have strlen() for finding the length of a string.
STRLEN(3) Linux Programmer's Manual STRLEN(3)
NAME
strlen - calculate the length of a string
SYNOPSIS
#include <string.h>
size_t strlen(const char *s);
DESCRIPTION
The strlen() function calculates the length of the string pointed to by
s, excluding the terminating null byte ('\0').
RETURN VALUE
The strlen() function returns the number of bytes in the string pointed
to by s.
To copy strings from a source buffer to a destination buffer, use the `strncpy()`
function. **Not the `strcpy()` function!
Here’s the documentation for strcpy and strncpy. Use the latter!
STRCPY(3) Linux Programmer's Manual STRCPY(3)
NAME
strcpy, strncpy - copy a string
SYNOPSIS
#include <string.h>
char *strcpy(char *dest, const char *src);
char *strncpy(char *dest, const char *src, size_t n);
DESCRIPTION
The strcpy() function copies the string pointed to by src, including
the terminating null byte ('\0'), to the buffer pointed to by dest.
The strings may not overlap, and the destination string dest must be
large enough to receive the copy. Beware of buffer overruns! (See
BUGS.)
The strncpy() function is similar, except that at most n bytes of src
are copied. Warning: If there is no null byte among the first n bytes
of src, the string placed in dest will not be null-terminated.
If the length of src is less than n, strncpy() writes additional null
bytes to dest to ensure that a total of n bytes are written.
RETURN VALUE
The strcpy() and strncpy() functions return a pointer to the destina‐
tion string dest.
BUGS
If the destination string of a strcpy() is not large enough, then any‐
thing might happen. Overflowing fixed-length string buffers is a fa‐
vorite cracker technique for taking complete control of the machine.
Any time a program reads or copies data into a buffer, the program
first needs to check that there's enough space. This may be unneces‐
sary if you can show that overflow is impossible, but be careful: pro‐
grams can get changed over time, in ways that may make the impossible
possible.
Again, do not use
strcpy()! Usestrncpy()with an explicit length to avoid dangerous bugs like buffer overflow! See theBUGSsection in the documentation above to understand why.Again x2, DO NOT USE
strcpy()!
Hints (for Making Your Life Easier)
To make this assignment easier to work with, you need to make sure you have a solid grasp on the following:
- using GDB, and
- memory layout of a linked list.
Dealing with pointers is hard, but it gets easier over time for sure. There is one important technique to accelerate this process: liberal use of memory diagrams.
In the coming weeks, you should aim to become very good at drawing memory diagrams. For now, we will show you an example tailored to this PA:
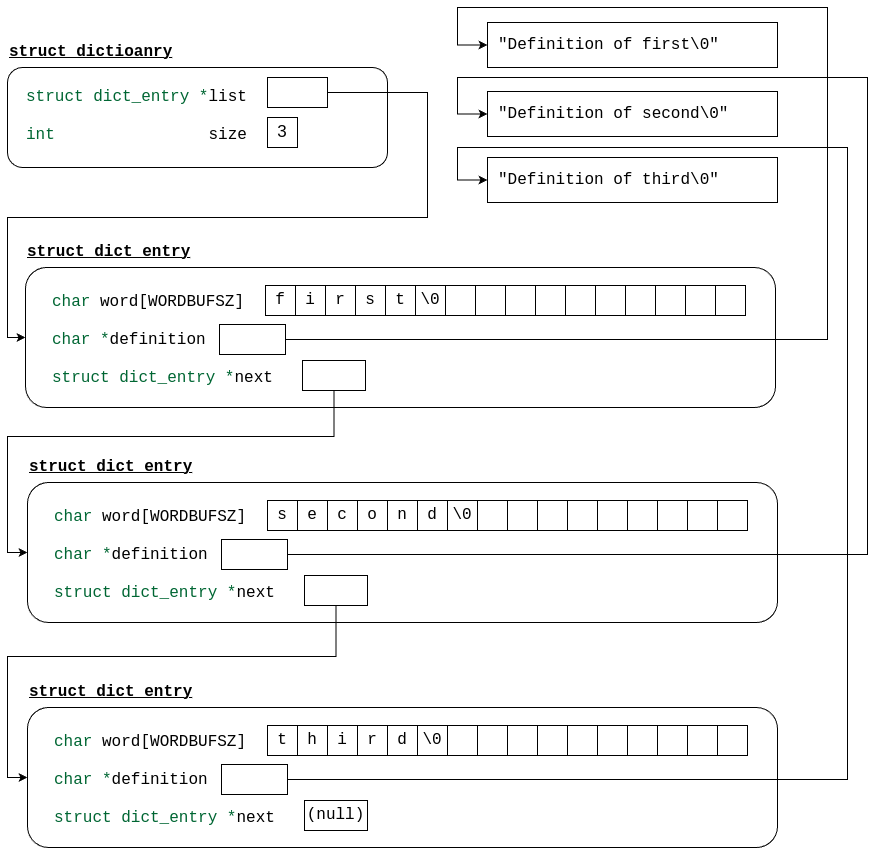
The diagram above shows the memory layout of a dictionary containing three words: "first", "second", and "third". Each arrow represents a pointer.
The dictionary itself is a struct dictionary. The size field has a value of 3 because there are 3 words in the dictionary. The list field points to the first entry, a struct dict_entry.
In each struct dict_entry, you can see the word is stored within the struct, but the definition is allocated separately using malloc. The next pointer points to the next entry in the dictionary, or NULL if the entry is at the end of the list.
Running A Script
When you are testing your program, it can be a lot of work to manually run commands every time you need to test your code. To overcome this inconvenience, we can create a file containing a sequence of commands, and use our old friend indirection to feed the file into our webster program to automatically run all these commands.
Here’s an example of a simple script. Let’s name this commands.txt:
load dict/short
show
insert word new definition
s word
quit
To feed this into the program:
$ ./webster < commands.txt
You can create different scripts based on your testing needs.
Finding Memory Errors
In this PA, you are very likely to run into various types of memory errors, and as we introduced in Discussion 4, valgrind is an excellent tool for finding memory errors.
In our autograder, we expect your code to run without any memory errors. (Most importantly, it should not have any memory leaks!) To make sure of that, you need to run valgrind yourself on your program:
$ valgrind --leak-check=full --track-origins=yes ./webster
To make things even easier, we can run it with a script (see previous section) so that we don’t have to type in commands when valgrind is running. Suppose you have a script named test_insert.txt:
$ valgrind --leak-check=full --track-origins=yes ./webster < test_insert.txt
Formatting Your Code
Let’s talk about coding style.
You probably have heard of the term before. Coding style dictates how source code is laid out in a file. As you read more and more code throughout your career, you will realize the importance of having a good and clean style.
It’s what makes this so hard to understand:
#include<stdio.h>
int main(){
int l;
printf("Enter a limit: ");
//scanf("%i", limit);
scanf("%d", &limit);
printf("Even numbers between 1 and %d:\n", limit);
for (int i=1;i<=l; i++) {
if (i%2 ==0) {
//printf(i);
printf( "%d ",i);
}
}
printf ("\n");
return 0;
}
…whereas this is nice, clean, and straightforward to read–
#include <stdio.h>
int main()
{
int limit;
printf("Enter a limit: ");
scanf("%d", &limit);
printf("Even numbers between 1 and %d:\n", limit);
for (int i = 1; i <= limit; i++) {
if (i % 2 == 0) {
printf("%d ", i);
}
}
printf("\n");
return 0;
}
The latter example is neat, well-indented, highly readable with well-named variables. The former is a bit of an unholy mess, which sadly we see too often in lab hours and office hours.
There is empirical evidence that poorly formatted code leads to more bugs!
Starting this PA, we are introducing a new requirement – code formatting.
But who has time to format their code all the time? I hear you ask. And indeed, it would be much easier to automate this process, which we will introduce next.
The clang-format tool
clang-format is a tool that automatically formats source files for languages like C, C++, JavaScript, etc. While it can often be integrated into an IDE or an editor like Visual Studio Code, we will simply run it from the command line.
The .clang-format configuration file
Just like the .vimrc file that you set up during lab, clang-format settings are also stored in a file: .clang-format is a hidden file in your repository that we have created. This file defines the coding style that your code will be formatted to.
The starter code you receive is formatted using this setting.
Running clang-format
In the directory with your C code, run the following command:
$ clang-format -i *.c *.h
This command runs the clang-format program. The -i flag tells it to modify the source files in place, which means changes will be made directly to the files. *.c *.h tells the program to format all files with the extension .c and .h.
If you have not seen this in lab already, the
*character is called a wildcard character. Basically, it means “all”.For instance, if we want to list all files in the directory starting with
test-:$ ls test-*Or, if we wish to remove all the files within the
output/directory:$ rm ./output/*This is a very useful tool for efficient terminal usage. Keep it in mind!
Submission
Again, please complete the mid-quarter survey (see first section) for 3% of your grade for this programming assignment.
Submitting from GitHub
First, make sure that the most up-to-date version of your code has been pushed to GitHub. If you want to double check, go to the GitHub web page and find your repository to make sure the code changes you made on ieng6 are actually all there.
Having done that, go to Gradescope and find the submission page for this PA. When you submit the assignment, you will see the option to submit from a specific GitHub repository. You will need to link your GitHub account first, after which you should be able to find your pa2 repository. Select it, and choose the main branch.
We have not discussed branching in git yet, so unless you know what you are doing, you should only see main for branch options.
Gradescope Autograder
We have changed our autograder so that you are able to see your final score when you submit, but you will not be able to see the hidden tests until after the grades have been released.
In this PA, we are also running some valgrind tests. So make sure you run valgrind on your code before submitting to gradescope.